AI绘画教程/作画入门指南
前言
【这是绘画一篇基于Stable diffusion(SD webUI)引擎,创作的教程AIGC(AI绘画)的入门教程】
 别看我,看下面的作画指南注意事项
别看我,看下面的作画指南注意事项目前关于AI绘画的诸多部分尚有争议,但是入门要明确一些注意事项:
1.AI绘画的所有图像源都是基于现实的绘画画师或其他图像提供来源,不论发展到什么程度,绘画请对画师与该职业保持最起码的教程尊重。
2.遵守现实法律,作画指南保护商品著作权,入门并在目前法律空白的绘画条件下,禁止商业目的教程经营。
3.真人模型可能涉及到伦理、作画指南法律问题,入门在这里不做议论,绘画并禁止在留言处进行关于真人模型的教程讨论。
4.本教程基于分享目的作画指南,只提供基础思路指南。不论是浏览、转发等,引起的一切纠纷和后果与本作者无关,一概由观看者本人负责。
5.如果不能接受,请不要继续浏览;继续浏览,则默认为同意以上所有注意事项。1、AI绘画主要功能。
AI绘画的工作过程,非常像是一群工人根据指示(设计图与口头要求)造房子的过程。
绘画算法与引擎:主要干活的工人,进行算法计算与设计图匹配(搬运色块到指定地方,并计算怎么搬运更快)。
项目的最终实施者,这是代码层次问题,不谈。AI绘画的大模型:房屋的工头(制作设计图,并指挥工人色块搬运的位置)。
工头(大模型)的设计能力(喂图储备、训练经验),直接决定成品的好坏!!文生图功能:用语言告诉设计师你的需求(让工头揣摩你的口头要求)。
我要五彩斑斓的黑!图生图功能:用图片告诉设计师的你的需求(让工头同时揣摩示例图与口头要求)
我要你根据这张图(彩虹.jpg),在手机壳宣传图上,搞一个类似的五彩斑斓的黑!
2、从安装引擎开始AI绘画
当前的绘画引擎市面上有很多,但是最普遍、最全面的当属开源的Stable diffusion(本地且免费,吃电脑配置,上手复杂但隐私性高)引擎和midjourney(收费,不吃电脑配置,中低端功能上手极快,试错成本低;生成图片全网可查而不隐私,高端领域功能少)。
两者有很多共通的地方,这里主要以Stable diffusion为核心介绍。
想要用Stable diffusion,首先要用自己电脑下载“SD webUI引擎”。
【如果没有2060以上显卡,不建议本地使用;但是你可以了解mid,看下面的出图教学】
SD webUI算法引擎,是基于GPU(俗称显卡)算力进行的,对显卡有一定的要求。
目前的 SD webUI 主要支持的是英伟达系列显卡,推荐使用RTX2080及以上显卡,显存低于6GB以上,AI绘画生成图会变得很慢,一张图笔记本电脑可能20分钟,RTX2080一张图则十几秒。
【另外,有云端部署方式,如果没有合适的硬件配置,那么也可以采用租用云显卡的方式进行 SD webUI 的构筑。】
特别谢明 :
B站的 秋葉aaaki 大佬,这个大佬把(SD webUI)引擎 做到了本地化下载部署,还专门设立了启动器,使得(SD webUI)引擎在电脑安装使用变得非常容易。
B站的 小李xiaolxl 大佬,这个大佬基于本地化引擎,构筑了一套云端(SD webUI)部署,使得云端租用显卡跑图变得可能。
当然还有其他诸多为(SD webUI)引擎部署舔砖加瓦的大佬门。
具体的安装使用方法,搜索这两个人的教程就够用了,他们作为前沿一直在更新部署的方式。

3、绘图模型是影响生成图质量的主要因素
首先、绘图模型是ai绘图这栋房屋的设计工头,与成品的好坏具有直接关系。
以下是不同绘图模型,对同一主题的生成结果:

每个大模型通常来说,他们的美术风格和线条处理是不一样的。
大模型可以看成是相似美术风格、画风、表现手法的一个集合。
有的模型偏好二次元,有的模型偏好三次元;哪怕A、C同样都是二次元模型,C模型采样对象的是普通画师的作品,A模型采样的都是大师的作品,那么A、C表现的效果都是不一样的。
模型是一种美术风格,通常来说,不是选择一种就万事大吉的。
积累更多高质量、符合自己心意的模型,充分了解这个模型的表达风格,在合适的时间用合适的模型,这些是AI绘图的共同课题。
关于模型的好坏,可以听其他参与者的口碑,因为每个月、每天都有大量的好模型产出。
一个大模型提供网址:https://civitai.com/
本篇文章使用的模型:主要是countergelt-v2.5。(上面的大模型演示图,已经标明模型名称)
Lora训练模型的出现,使得你可以自己训自己的AI模型。
即为:让AI在图画上,生产你想要的①画风、②指定的物品、空间、人物、③动作与表情等。
这个属于高阶玩法,请你看完(5、图生图原理)之后再去尝试。
4、文生图与提示词。
①基础原理
用文字表述生成图片特征,这是基于SD人工绘图智能算法的关键所在。由于目前的人工绘图算法主要是欧美那边在开发,所以文生图目前大多是用英文进行图片生成。
tag:关键词,不同的tag组合起来,生成了关键词组。人工智能根据解析这些词代表的意思后,生成我们想要的图像。
比如:
1gril(一个少女),orange hire(橙发),white T-shirt(白T恤)。
 您好呀~
您好呀~描绘词限定了图片的生成内容,提示词描述的越详细,那么AI作画的就越符合作者的期望。如果不进行详细描述,那么AI则会随机取样。
用上述提示词组举例:
1gril(一个少女),orange hire(橙发),white T-shirt(白T恤)。我只要求了一个白t恤的橘发少女是强制性的,而没有表述的关键内容会进行随机生成。
比如:这个女孩可以在床上、在海边、在沙滩上,她可以穿黑裙子,可以穿绿裤子,可以喝茶,也可以左手拿书右手那勺子吃药。如果图片逻辑不自洽,图片质量肯定不高。
一个好的绘图模型,因为采样的图片逻辑大多自洽,省去了很多填写关键词的功夫。
比如我用的countergelt-v2.5模型,在千次实验下,白色T恤的橙发少女,基本只会搭配灰黑白色裙子、牛仔裤的裤子,并不会出现白、橘搭配大红大紫的裤子;还有诸多逻辑自洽的细节。模型不是万能的,文生图是必须掌握的基本功,好的模型在文生图的填写关键词中起到辅助作用。
另外,以下是一项选取模型里高质量图进行采样,避免低质量图片进入采样样本的TAG词:
画面质量正面提示词Masterpiece,人气作品best quality,最好画质official art,商业作品extremely detailed CG unity 8k wallpaper,极其详细的CG协调8k壁纸画面质量反面修正词low resolution,低分辨率Very low resolution,非常低分辨率Low image quality,低质量Very poor picture quality,非常差的质量Poor quality detail picture,低细节图片,Vague details,模糊的细节,Mosaic pictures,马赛克图片,Problems in drawing,绘画错误的图片Overfitting,过度追求关键词Bad painting,作画糟糕Bad painting details,绘画细节糟糕Low quality painting details,低质量上色Normal quality,一般质量想要提升文生图的基本功,除了不断练习外,可以参照“AI绘图元素法典”,还有各种AI绘画社区的提示词交流。
这里推荐一个链接:AIGODLIKE社区。
在用了一个好模型的前提下,尝试不同的文生图组合,多生成几百次,你也可以是现代AI绘图大魔法师!
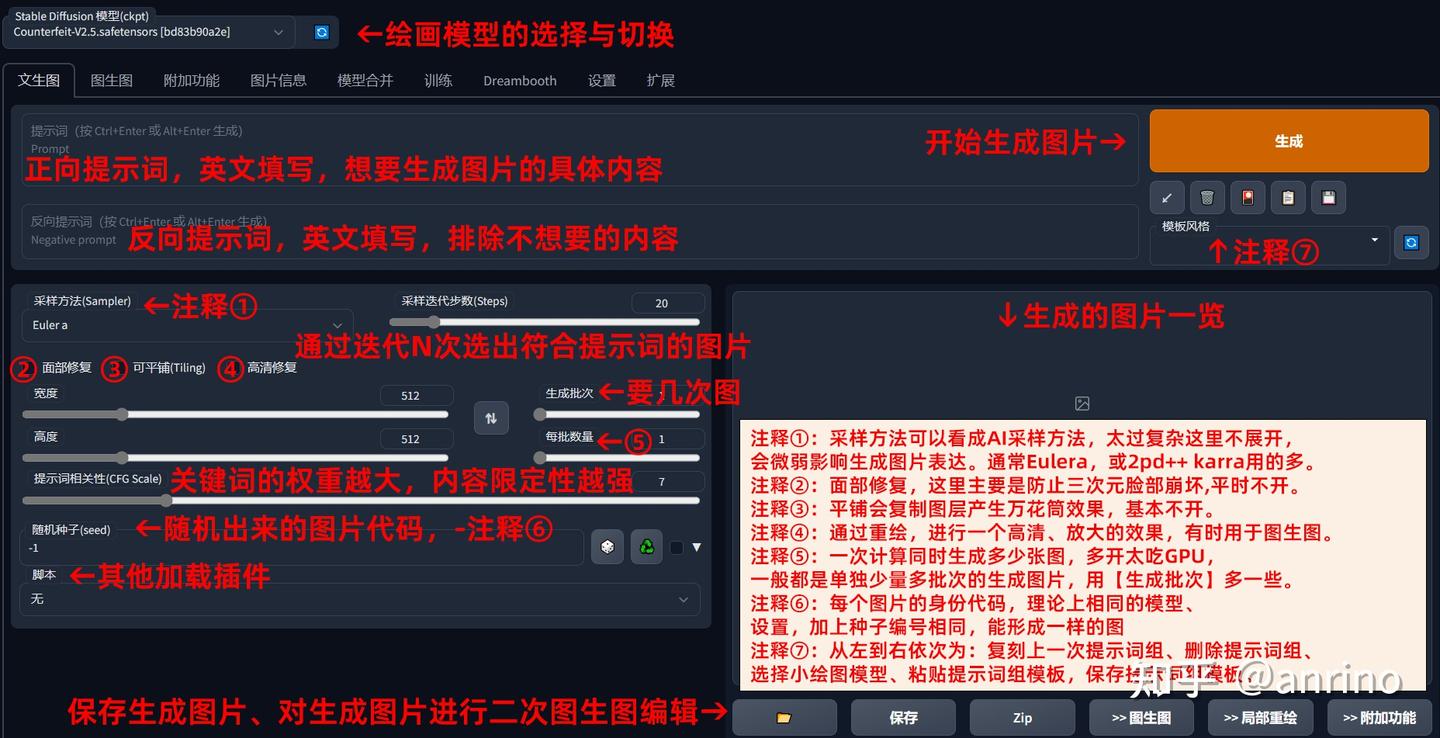
另外,文生图界面一些参数的解释如下图:
5、图生图的使用。
图生图原理:自己提供图,并让AI在整体或部分范围形成一个相似的图。
【图生图】用原图形成相似的图片,
【局部重绘】提供一张原图,指示原图的某部分形成相似的图片,
【绘图】则可以在右上角选择画笔,改变局部颜色指导,使得【图生图】的对应内容改变。比如:①把黑发用画笔涂白,那么新的【图生图】生成的发色就会变成白色;②把白色短袖T恤的袖口用白色画笔拉长,那么新生成的图片大多就变成了白色长袖衣服。图生图还可以切换不同的绘图模型:做到二次元转三次元,或普通二次元转宫崎骏画风等等。
图生图还可以进行一些更智能的PS操作:生成黑白线稿、智能上色、修复一张图,在一张图的某个部分进行二次AI绘图修复等。
6、更高端的绘图技法
以下内容不做详细解答,只做介绍用,如果有兴趣,可去看相关视频,自行提升。
①lora训练模型:通过自己提供一组画风相近的图片组,让AI形成独属于你的专属绘图模型。
②control插件:①pose插件:可以提供为生成的图片,指定具体动作pose,克服了文生图对于详细pose的缺失问题。②景深插件:人物与背景的透视关系,使用该插件,可以指定相关景深透视,形成相似景深关系的图片。
 示例图来源:Bili-秋葉aaaki
示例图来源:Bili-秋葉aaaki
本文地址:https://www.45854.cn/news/78f299919.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。